浅谈测试过程中的数据构造
常见的测试数据构造方式及优缺点
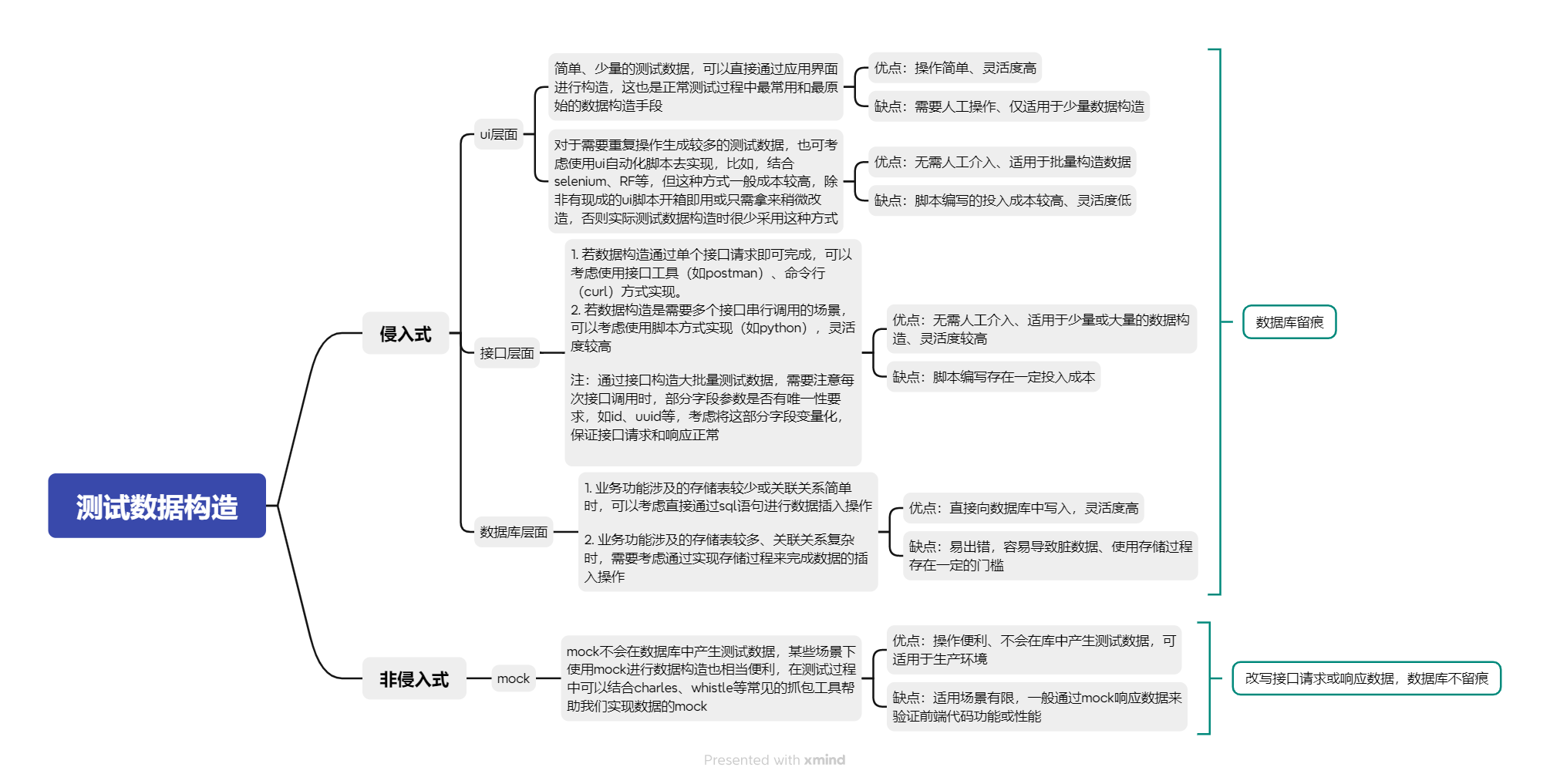
一、ui层面
按照实际业务流程,直接在应用界面上操作,构造测试数据
略
通过编写ui自动化脚本,模拟通过应用界面上点击的方式构造大量测试数据
略
二、接口层面
通过借助接口测试工具或使用curl命令行的方式向接口发送请求,构造测试数据,请求内容可以通过浏览器的开发者工具(F12)或者其他抓包工具进行抓包,并复制为curl请求,然后导入到postman等接口测试工具或者直接打开cmd命令行执行curl命令完成请求。
eg. 将复制的curl请求导入到postman,根据需要修改请求数据并进行接口请求
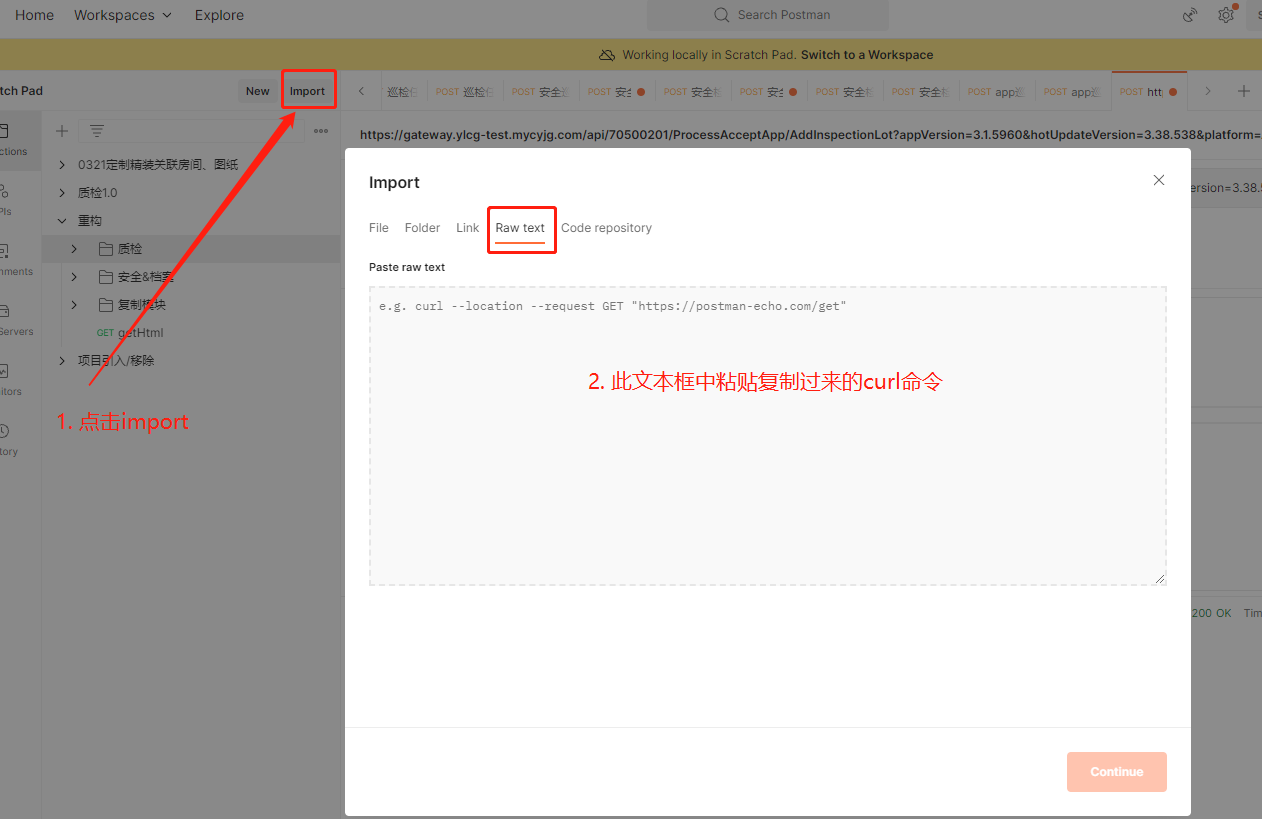
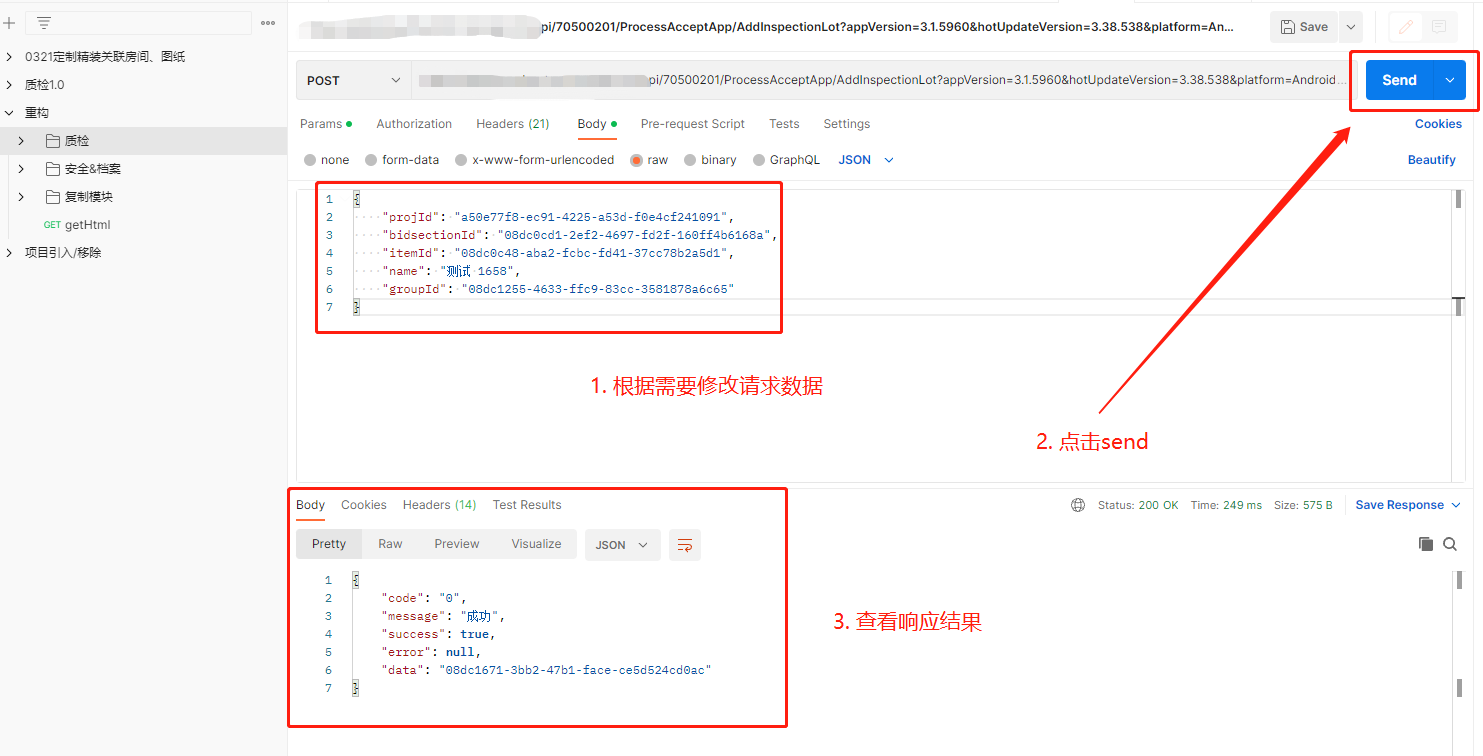
eg. 对应的curl请求(部分关键信息已屏蔽,使用xxxx替代)
1
curl -X POST "https://xxxx.com/api/70500201/ProcessAcceptApp/AddInspectionLot?appVersion=3.1.5960&hotUpdateVersion=3.38.538&platform=Android&_LogUserCode=17561729602&extKey=extProcess&extValue=gxys&extBizUnitCode=70500203" -H "host: xxxx" -H "accept: application/json, text/plain, */*" -H "tenantcode: xxxx" -H "user-agent: Mozilla/5.0 (Linux; Android 13; PEDM00 Build/TP1A.220905.001; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/103.0.5060.129 Mobile Safari/537.36 CordovaWebViewEngine" -H "apptoken: xxxx" -H "appcode: 7050" -H "content-type: application/json" -H "x-requested-with: com.mysoft.chanyeapp" -H "sec-fetch-site: cross-site" -H "sec-fetch-mode: cors" -H "sec-fetch-dest: empty" -H "accept-language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7" -H "Connection: close" -d '{"projId":"a50e77f8-ec91-4225-a53d-f0e4cf241091","bidsectionId":"08dc0cd1-2ef2-4697-fd2f-160ff4b6168a","itemId":"08dc0c48-aba2-fcbc-fd41-37cc78b2a5d1","name":"测试 1657","groupId":"08dc1255-4633-ffc9-83cc-3581878a6c65"}'
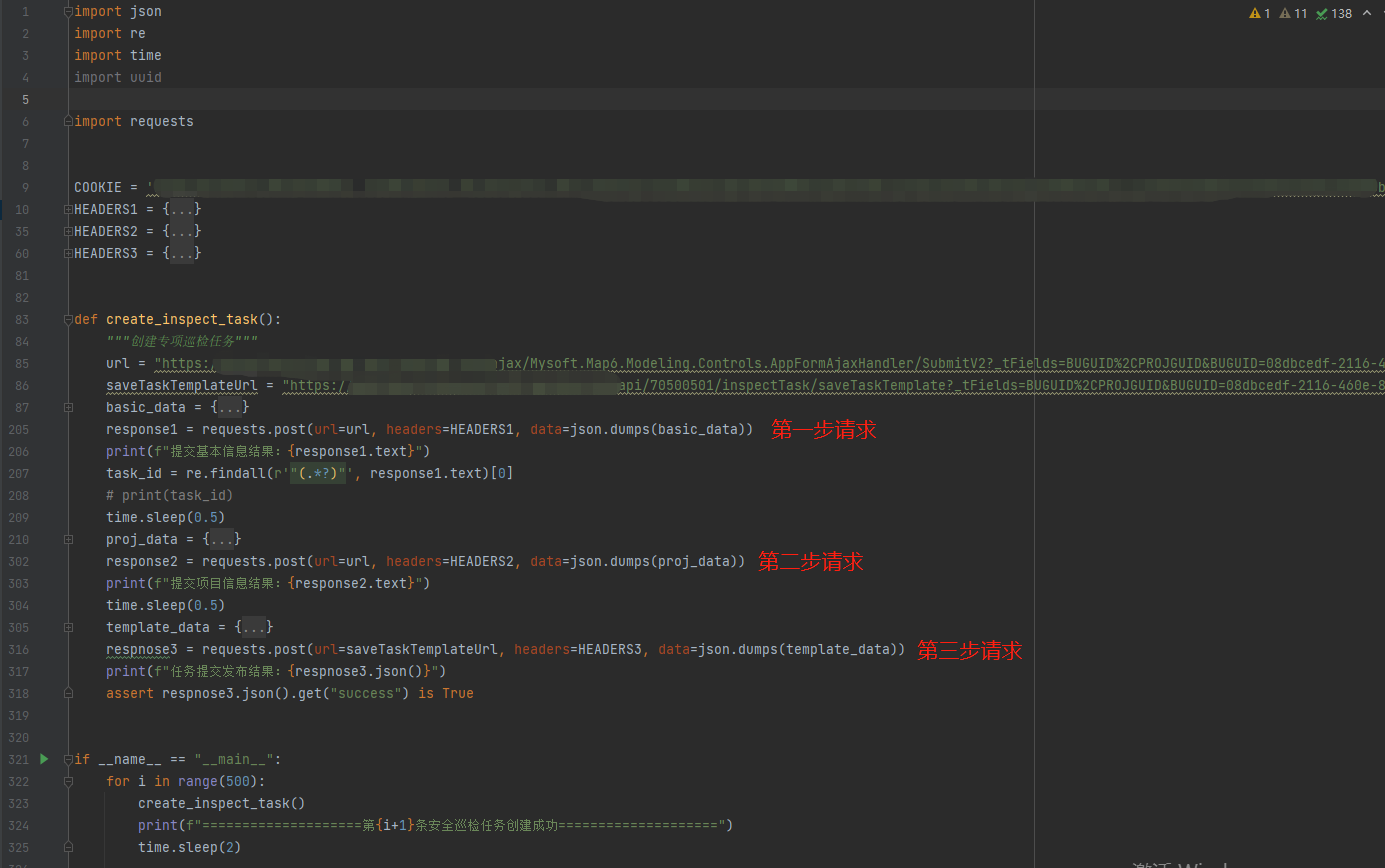
通过python脚本串联起多个请求,构造完整的业务请求场景来批量构造测试数据,如下为基于实际业务的一段demo脚本
三、数据库层面
明确业务数据存储使用的表且表结构简单、关联关系较少、只需构造少量测试数据的情况下,可直接使用insert或update语句插入或改写表中数据来完成数据构造。
eg. 存在这样一个业务场景,在pc端新建完一条内容后,用户可以在app端浏览该内容,并且后台会统计该内容的浏览量和浏览人数。
a. 分析:如果针对这个场景来构造不同用户的浏览数据的话,直接向数据库中写数据是最简单的办法,因为涉及到不同用户操作,通过ui或接口层面进行数据构造势必会遇到多账号切换、不同cookie鉴权等问题。
明确使用sql造数据后,我们要确认涉及到的表结构,实际业务存在一张浏览记录表,记录不同用户对不同内容的浏览数据,而且通过这张表计算出某一条内容的浏览人数和浏览量并冗余到内容主表里,来提高实际处理性能。
b. 编写sql:由上,我们可以确认数据构造涉及一条insert和一条update语句,先向浏览记录表插入一条浏览数据,然后更新内容主表该条内容的浏览量和浏览人数。
1
2
3
4
5
6
7
8
9#向用户浏览记录表插入数据
INSERT INTO `xxxx_postuserviews`(`postId`, `userId`, `postUserViewsGUID`, `CreatedTime`, `CreatedGUID`, `CreatedName`, `ModifiedTime`, `ModifiedGUID`, `ModifiedName`, `VersionNumber`) VALUES (${postId}, ${userId}, UUID(), fn_timezone_getdate(), ${userId}, ${userName}, fn_timezone_getdate(), ${userId}, ${userName}, fn_timezone_getdate());
#查询浏览记录表计算出某条内容的浏览量和浏览人数
SELECT count(postId) FROM `xxxx_postuserviews` WHERE postId = ${postId};
SELECT count(DISTINCT(userId)) FROM `xxxx_postuserviews` WHERE postId = ${postId};
#更新内容主表该内容的浏览量和浏览人数
UPDATE `xxxx_posts` SET pageView = xx, userView = xx, ModifiedTime = fn_timezone_getdate() WHERE postsGUID = ${postId};如果涉及的业务关联表较多,且需要通过sql批量构造测试数据,那么可以考虑定义一个存储过程,通过一组sql集合来构造我们需要的测试数据。
eg. 在上述业务场景的基础之上,内容还被划分为仅浏览和待学习两种类型,待学习的内容需要用户在页面停留超过指定时长计为完成学习,并且后台会统计用户的实际学习时长。
a. 分析:如果我们需要批量构造不同用户的学习记录,那么我们不仅要构造浏览记录数据,还需要构造用户的学习记录和学习时长数据。实际业务中,用到了学习记录表和学习时长记录表分别用来记录不同用户对不同内容的学习记录和学习时长,由此可见,这里共涉及到四张表的写操作,分别为浏览记录表、学习记录表、学习时长记录表和内容主表,另外,我们还要通过查询用户表来获取我们要用到的用户数据。
b. 编写存储过程:由上,我们可以明确sql集的处理思路,第一步,在用户表中随机查询一名用户并判断该用户是否存在学习记录,第二步,若用户不存在学习记录,那么向学习记录表、时长记录表和浏览表中插入数据;若用户存在学习记录,开始下一次循环并继续查找用户,第三步,完成指定循环次数的前两步后,更新内容主表该内容的浏览量和浏览人数。
调用存储过程时,我们需要传入一个参数max_num,来指定循环次数,可近似为测试数据量(因为不一定每次循环都会构造一条测试数据)
1
2#调用存储过程
call insert_postLearning(100);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36#定义存储过程
CREATE DEFINER=`ops_rw`@`%` PROCEDURE `insert_postLearning`(IN `max_num` int)
BEGIN
#Routine body goes here...
DECLARE i INT DEFAULT 0;
DECLARE userGuid1 CHAR(36);
DECLARE userName1 VARCHAR(128) DEFAULT 'sql造数据';
DECLARE is_learning INT DEFAULT 0;
DECLARE pageView1 INT;
DECLARE userView1 INT;
SET autocommit = 0;
REPEAT
SET i = i + 1;
SET is_learning = 0;
#随机查询一名用户
SELECT userGUID, userName INTO userGuid1, userName1 FROM `myuser` ORDER BY RAND() LIMIT 1;
#查询是否存在该用户的学习记录
SELECT count(*) INTO is_learning FROM `xxxx_postuserlearnings` WHERE userId = userGuid1 AND postId = 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx';
#判断是否已存在学习记录
IF (is_learning = 0) THEN
#向学习记录表插入数据
INSERT INTO `xxxx_postuserlearnings`(`postId`, `userId`, `postUserLearningsGUID`, `CreatedTime`, `CreatedGUID`, `CreatedName`, `ModifiedTime`, `ModifiedGUID`, `ModifiedName`, `VersionNumber`) VALUES ('xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', userGuid1, UUID(), fn_timezone_getdate(), userGuid1, userName1, fn_timezone_getdate(), userGuid1, userName1, fn_timezone_getdate());
#向学习时长记录表插入数据
INSERT INTO `xxxx_postlearningtime`(`postId`, `userId`, `type`, `time`, `maxTime`, `moduleCode`, `postLearningTimeGUID`, `CreatedTime`, `CreatedGUID`, `CreatedName`, `ModifiedTime`, `ModifiedGUID`, `ModifiedName`, `VersionNumber`) VALUES ('xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', userGuid1, 1, FLOOR(RAND() * (1000) + 1), 600, '', UUID(), fn_timezone_getdate(), userGuid1, userName1, fn_timezone_getdate(), userGuid1, userName1, fn_timezone_getdate());
#向用户浏览记录表插入数据
INSERT INTO `xxxx_postuserviews`(`postId`, `userId`, `postUserViewsGUID`, `CreatedTime`, `CreatedGUID`, `CreatedName`, `ModifiedTime`, `ModifiedGUID`, `ModifiedName`, `VersionNumber`) VALUES ('xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', userGuid1, UUID(), fn_timezone_getdate(), userGuid1, userName1, fn_timezone_getdate(), userGuid1, userName1, fn_timezone_getdate());
END IF;
COMMIT;
UNTIL i = max_num
END REPEAT;
# 更新主表的阅读人数和阅读量字段
SELECT count(postId) INTO pageView1 FROM `xxxx_postuserviews` WHERE postId = 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx';
SELECT count(DISTINCT(userId)) INTO userView1 FROM `xxxx_postuserviews` WHERE postId = 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx';
UPDATE `xxxx_posts` SET pageView = pageView1, userView = userView1, ModifiedTime = fn_timezone_getdate() WHERE postsGUID = 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx';
COMMIT;
END
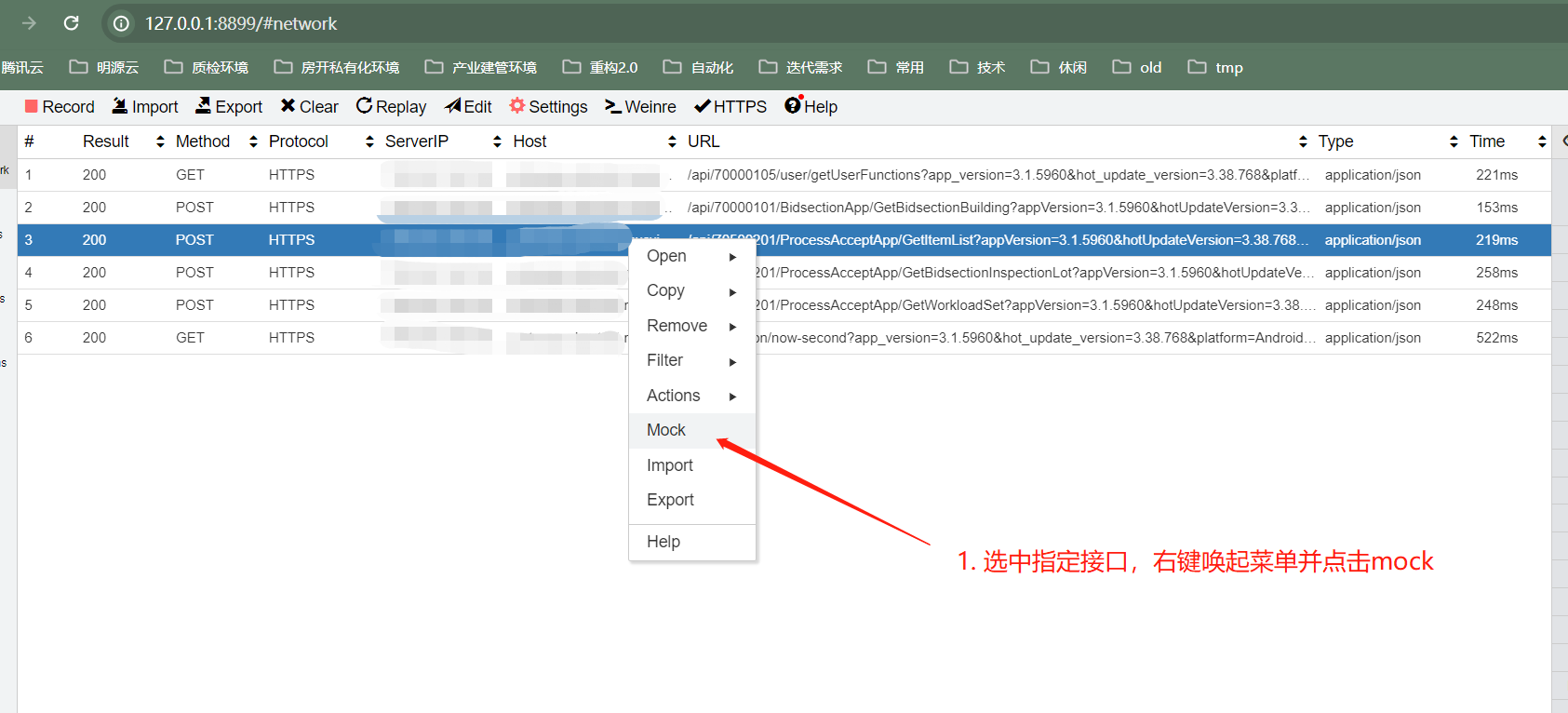
四、mock
如果在测试过程中,我们不想通过以上方式去构造测试数据,而且测试场景只关注前端对于数据的处理或前端渲染、加载速度,那么我们可以考虑通过mock响应数据来满足我们的要求。
mock的方式有很多,现在常见的一些抓包工具,比如,charles、fiddler或者whistle都支持mock的功能,这里以whistle为例,介绍一下mock的基本使用方式。whistle 是一个跨平台的抓包与 web debug 工具,结合chrome的SwitchyOmega插件,可以轻松实现web应用请求的抓包、修改等操作。关于whistle的安装使用可以参考whistle安装与使用,关于whistle的更多使用细节可跳转至whistle官方文档查阅,这里不做过多赘述。
a. 将mock的响应内容定义到whistle自带的values
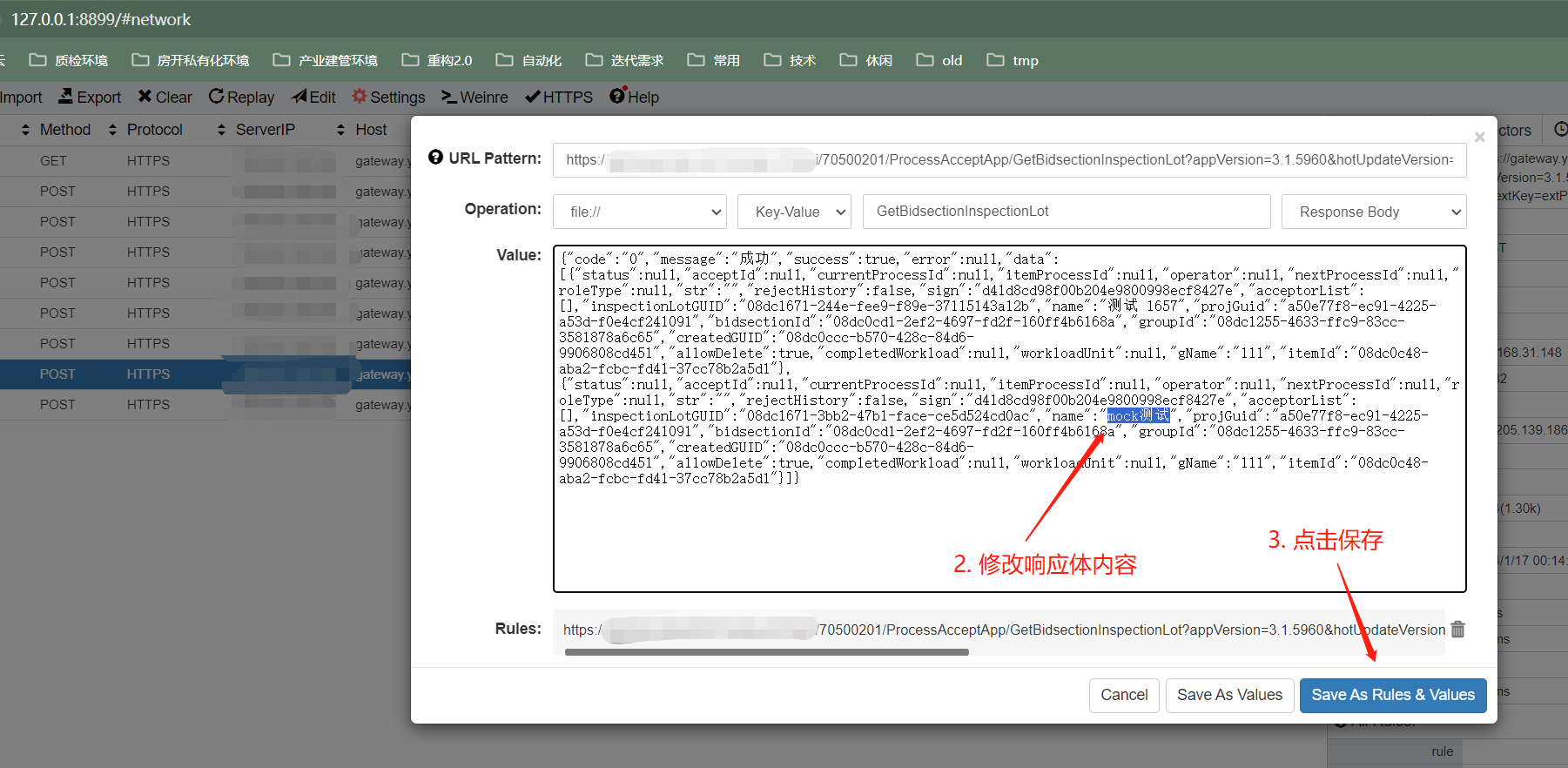
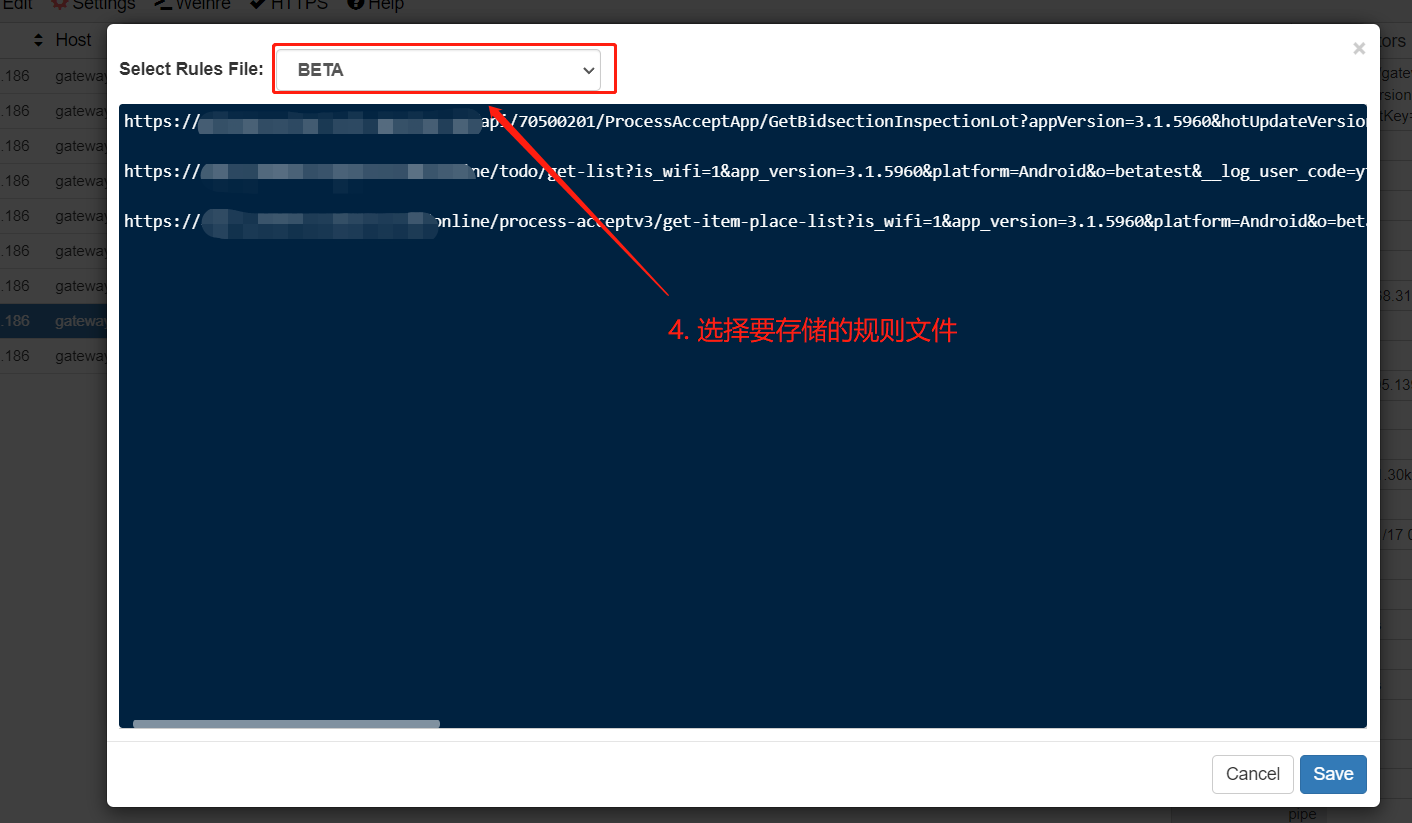
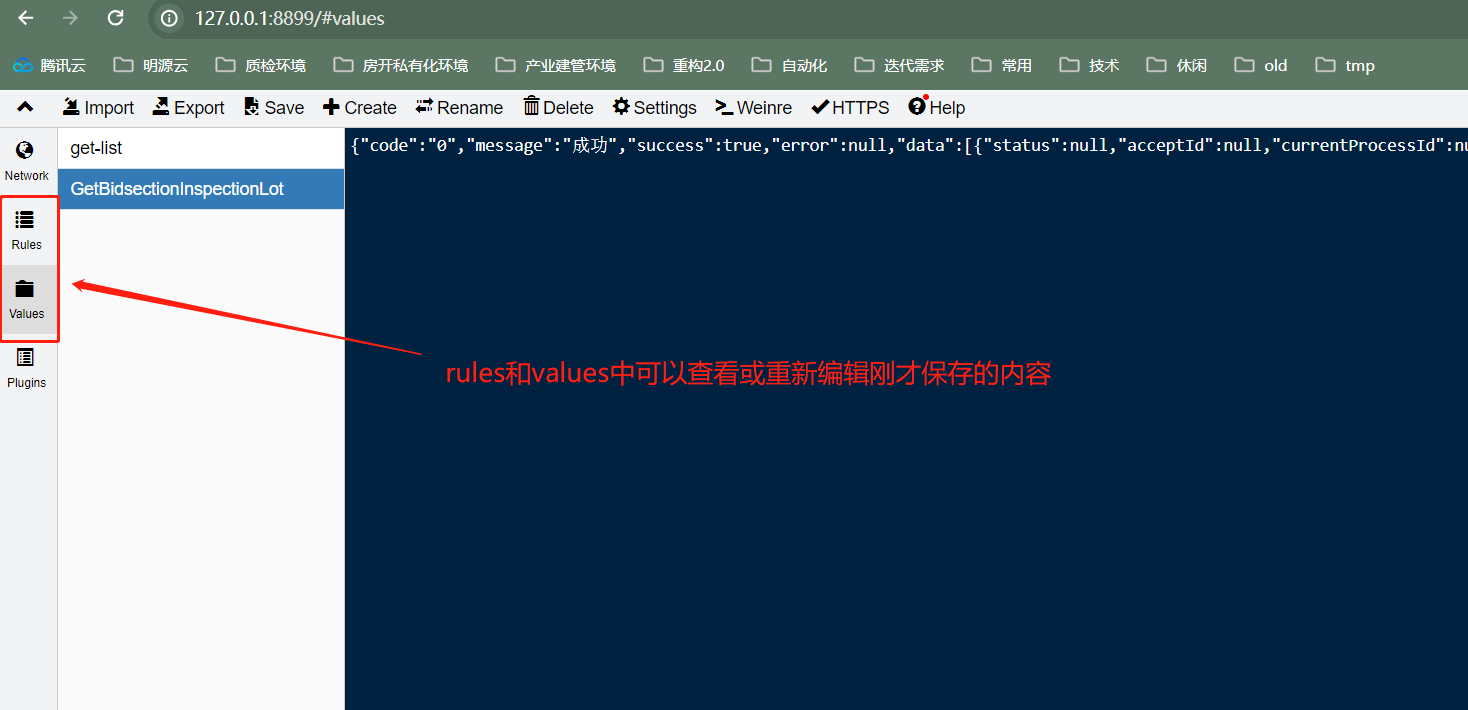
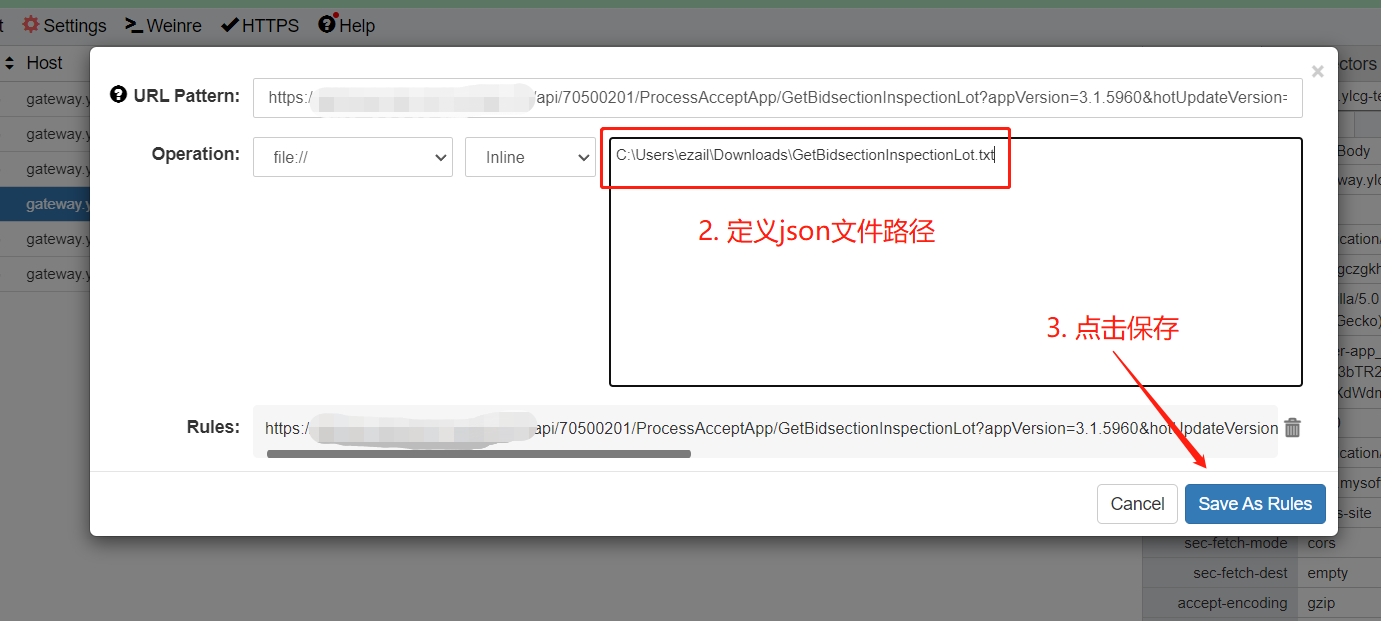
b. 将mock响应内容定义为本地json文件
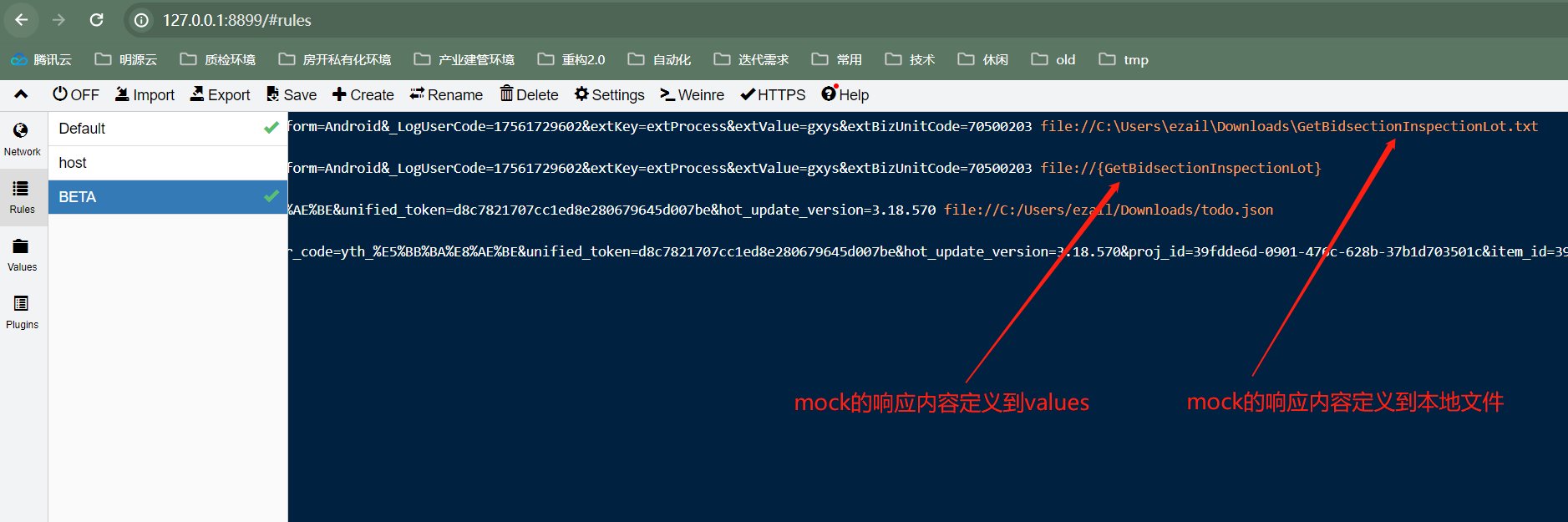
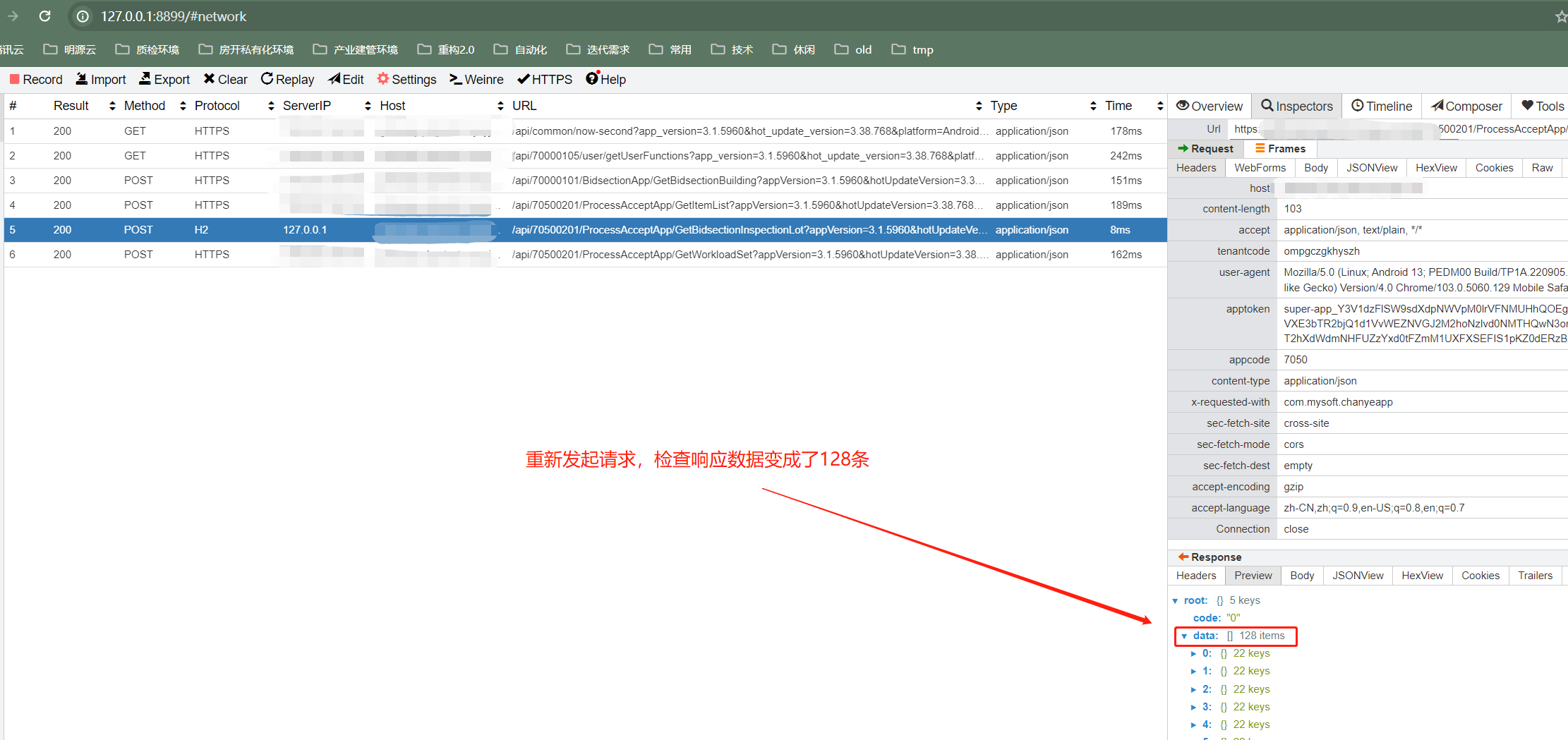
c. 如果实际接口返回数据量较少,而我们想通过mock较多的响应数据来测试前端的渲染或加载性能,该怎么办呢?这个时候,我们可以通过shell的jq命令来对json数据进行处理,扩充接口响应的数据量。
1
2
3
4
5
6
7
8读取原文件中的json数据,赋值给变量raw
raw=$(cat GetBidsectionInspectionLot.txt)
对变量raw中的data进行自增操作
raw=$(echo "$raw" | jq '.data+=.data')
将修改后变量raw的内容写入新的json文件
echo $raw > GetBidsectionInspectionLot.json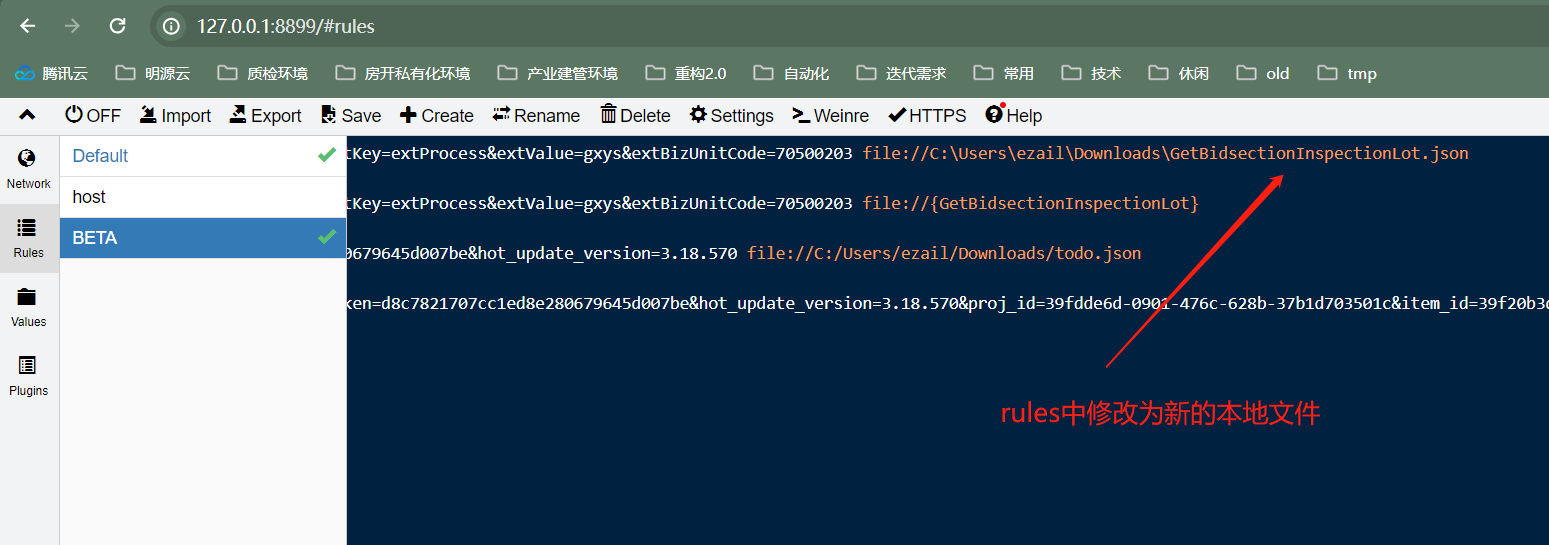
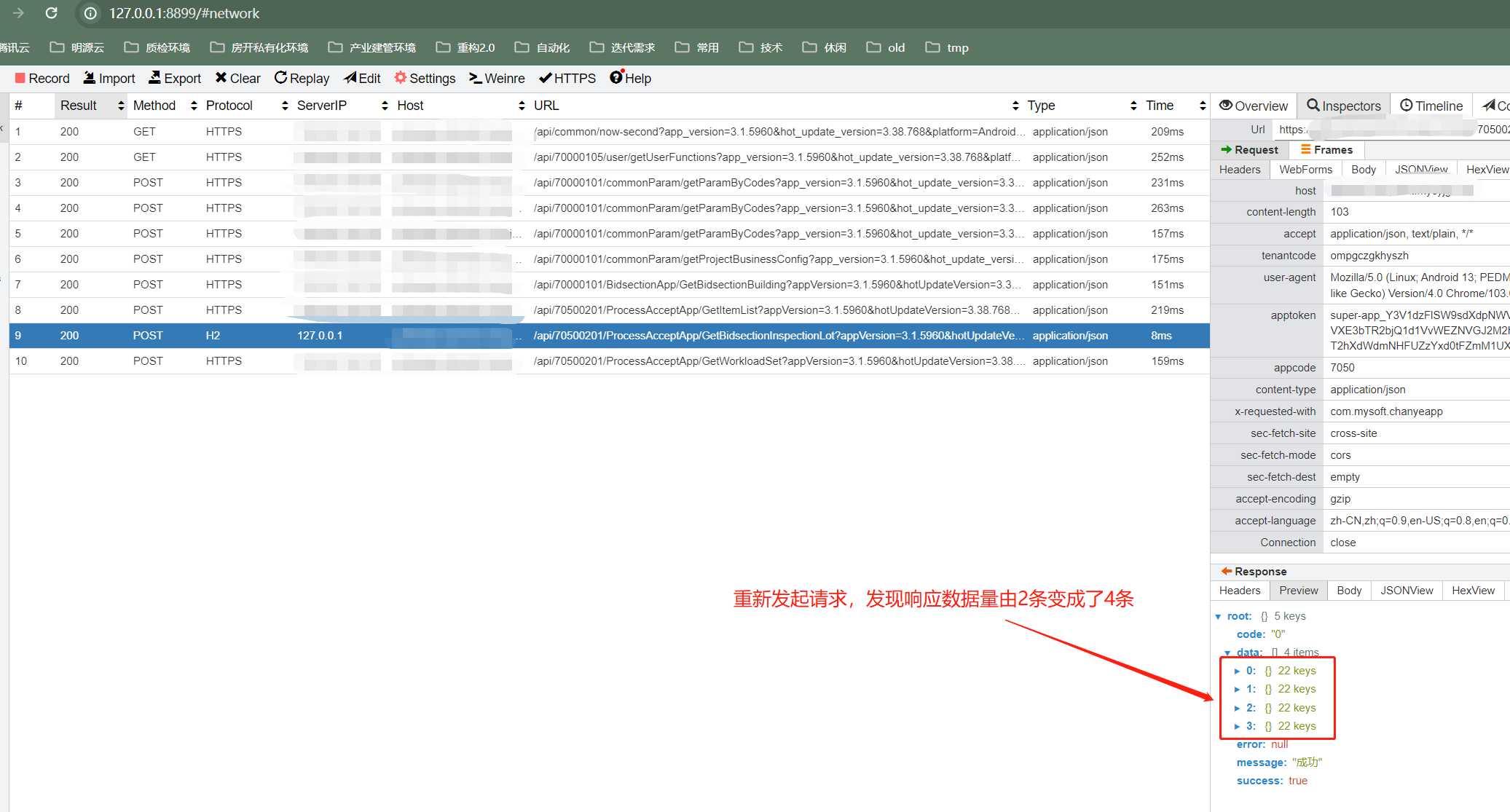
d. 如果想要mock响应返回更多的数据,该如何构造呢?我们可以定义一个shell脚本,循环处理进行响应数据的自增,示例如下
1
2
3
4
5
6
7
8
9! /bin/bash
raw=$(cat GetBidsectionInspectionLot.json)
for i in `seq 5`
do
raw=$(echo "$raw" | jq '.data+=.data')
done
echo "$raw" > GetBidsectionInspectionLot.json
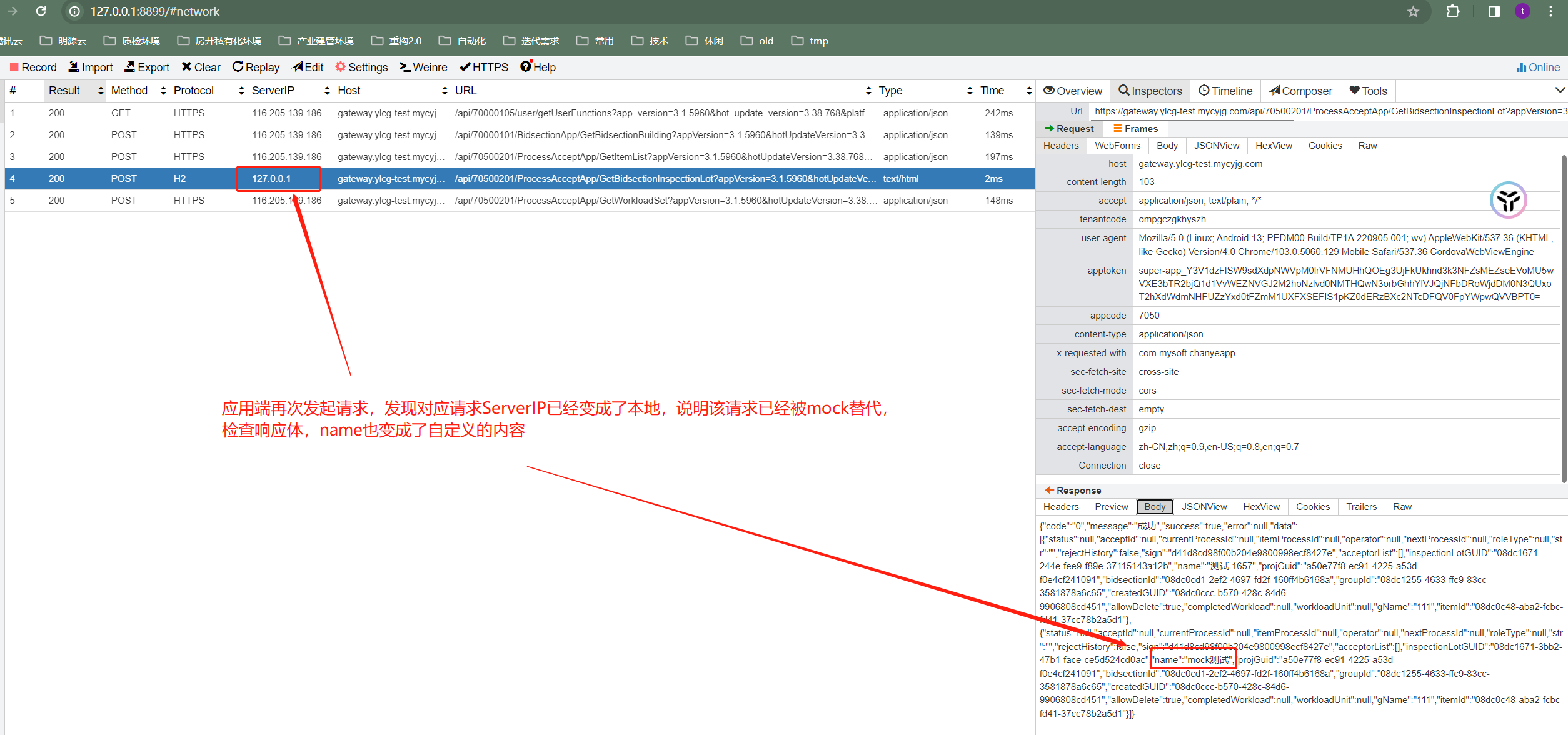
执行脚本后,再次发起请求